
딥러닝이란?
= 사람의 신경망을 모방하여 기계가 병렬적 다층 구조를 통해 학습하도록 만든 기술
기계도 사람처럼 생각하게 하기 위해 뉴런을 만들어 생각하게 해보자는 것이
제일 이해하기 쉽게 딥러닝을 설명할 수 있는 방법입니다.
딥러닝은 컴퓨터가 많은 뉴런(선형모델, 즉 퍼셉트론)의 결과를 종합하여 판단을 하는 모델입니다.
딥러닝은 많은 선형모델들이 모여서 구성하고 있습니다. 많은 선형모델은 많은 생각의 가짓수를 뜻합니다.
선형 모델 하나하나 각각은 y=wx+b의 식을 가지는 선형모델이며 각 각 선형모델마다 판단한 결과를 출력합니다.
딥러닝의 특징
- 모델을 사용자가 직접 설계하며 설계하기위해 많은 코드가 필요함
- 처음 사용하는 가중치를 랜덤하게 배정하기 때문에 재시작할때마다 최종 결과값또한
여러번 실행할수록 조금씩 달라질 수 있다.
- 퍼셉트론으로 구성되어 있다.
추상적이고 느슨한 결과를 기계한테 정해진 답만을 내리게 했다면 사람처럼 생각할 수 있는 가짓수를 늘린것과 같습니다. 결과를 종합해서 판단을 하게 한다면 기계도 사람처럼 느슨한 판단의 경계를 가질 수 있기 때문입니다.
✅ Rule-based expert system VS Machine Learning VS Deep Learning

- 딥러닝과 머신러닝간의 장단점 구분
어떤문제이냐에 따라서 머신러닝이 더 좋을수도 있음
딥러닝(Deep Learing)은 컴퓨터비젼, 음성인식, 자연어처리, 신호처리 등의 분야에 두각을 나타냄.
기존 머신러닝은 2차원의 데이터에 두각을 나타낸다.
✅ 머신러닝 vs 딥러닝
기존 머신러닝과 딥러닝의 공통점으로는 데이터를 입력하고 알고리즘이 계산하고 예측해서 예측값을 뽑아내는 것이다. 또한 차이점으로 예측값과 오차값을 빼서 loss function을 계산할 때,
머신러닝에선 예측의 정확도가 안좋으면 사람이 직접 그리드서치나 하이퍼파라미터를 통해 튜닝했지만
딥러닝은 optimizer라는 과정을 한번 더 거쳐 결과값이 좋아질때까지 스스로 학습을 진행한다.
즉, 반복하는 작업이 딥러닝에 추가되는 것이 다른 것이다.

따라서 딥러닝은 사람의 개입이 최소화된 모델이다. (feature engineering이 거의 필요없음)
모델은 원한만큼의 결과값이 출력되면 performance measure라는 최종출력값으로 뽑아내며
딥러닝의 알고리즘에는 퍼셉트론, CNN, ANN이 있다.
✅ Keras 란?
Keras는 Tensorflow아래에 keras가 하위 모듈로 구현되어있는 모델이다.
다양한 뉴럴 네트워크 모델을 미리 지원하고 있어 Keras는 코드 뭉탱이들을 블록으로 만들어두고
네트워크를 조립하듯이 만들면 된다. 그냥 블록을 조립하듯이 네트워크를 만들면 되어
전반적인 네트워크를 구조를 생각하고 작성한다면 빠른시간 내에 코딩을 할 수 있다는 장점이 있다.
✅ 퍼셉트론이란?
퍼셉트론이란 들어온 데이터에 대해서 판단한 뒤, 역치 이상의 값이 나온다면 1으로 반응하고 아니라면 0으로 반응한다.

- 처음 가중치는 랜덤으로 책정된다.
- 가중치(w) = 각 입력신호가 결과에 주는 영향력을 조절하는 매개변수
- 편향(b) = 뉴런이 얼마나 쉽게 활성화하느냐를 조절하는 매개변수
- 활성화 함수(sigmoid, relu, softmax... 등)에 집어넣어서 예측값을 계산한다. 활성화 함수는 따로 또 다룬다.
- 이 퍼셉트론이 중간에 있는 퍼셉트론이면 예측값 끝에 퍼셉트론이 연결되어있고 만약 최종 퍼셉트론이라면 이 퍼셉트론의 예측값이 예측값이 된다
- 한계점 : AND, OR 게이트는 해결이 가능하지만 간단한 XOR문제를 해결할 수 없다.
- 해결을 위해 다층 퍼셉트론 사용

✅ 다층 퍼셉트론이란?
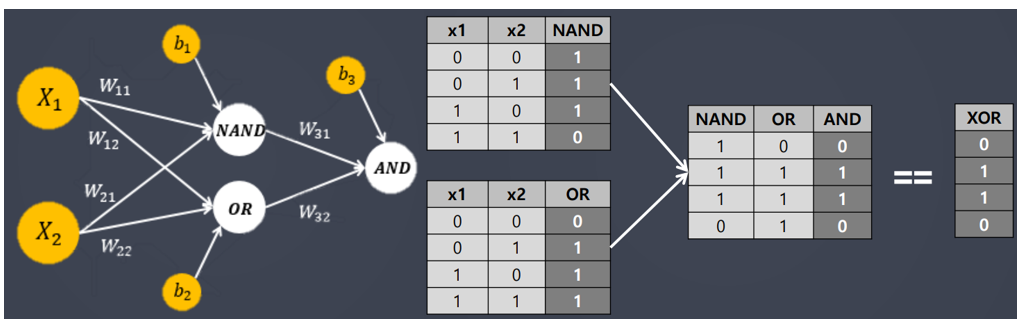
- 처음 가중치는 랜덤으로 책정된다.
- 가중치(w) = 각 입력신호가 결과에 주는 영향력을 조절하는 매개변수
- 편향(b) = 뉴런이 얼마나 쉽게 활성화하느냐를 조절하는 매개변수
- 장점
- 비선형 데이터를 분리할 수 있다.
- 단점
- 학습시간이 오래 걸린다.
- 가중치 파라미터가 많아 과적합되기 쉽다.
- 가중치 초기값에 민감하며 지역 최저점에 빠지기 쉽다.
✅ 딥러닝 process
- 문제 정의 : 와인 종류 분류
- 데이터 수집
- 데이터 전처리
- 거의 필요 없음
- 결측치 처리만 담당하면 됨
- 정규화, column끼리 뭉쳐서 새로운 컬럼, 등등을 모델이 알아서 해줌.
from sklearn import datasets
wine = datasets.load_wine()
wine.keys()
#분석에 사용할 데이터와 특성들 이름
wine['feature_names']
#문제
X = pd.DataFrame(wine['data'], columns= wine['feature_names'])
#정답
y = wine['target']- 탐색적 데이터 분석 (EDA)
- 거의 필요없음.
- 사용하는 데이터가 어떤것이냐에 따라 방법들이 무궁무진함
- hsv (명도 채도 조도) , 흑백/컬러 중에서 여러가지로 나뉘게 되고 데이터를 어떻게 바라볼 것인가.
주가 되는 색깔을 어떻게 처리할 것인가. 등등 이미지와 영상처리, 음성처리 등을 배우게 된다. - ex : 테두리 출력 이미지 안에서 내가 원하는 객체 탐색
- 모델 선택 및 하이퍼 파라미터 튜닝(모델 설계는 층을 많이 쌓을수록 무거운 모델)
- 모델 설계 시 제어하는 parameter 상세 설명
- 뉴런의 수(units) : 생각하는 가짓수 (30 = 30개의 뉴런을 생성하겠다.)
- input_dim : 입력하는 데이터의 가짓수 (input_dim = 13 : 13가지의 데이터 columns 가 들어갈것이다.)
- activation : 활성화 함수. 즉 생각하는 방법 (activation = 'relu' : relu라는 방법으로 생각해봐라.)
- 모델 설계 시 제어하는 parameter 상세 설명
from tensorflow.keras.models import Sequential # 딥러닝 모델 생성
from tensorflow.keras.layers import Dense # 딥러닝 모델 설계
#모델 생성
model = Sequential()
#1층
model.add(Dense(units = 30, input_dim = 13, activation = 'relu')) #하나의 뉴런을 생성함
#2층
model.add(Dense(units = 12, activation = 'relu'))
#결론 출력하는 층 = 마지막 층
model.add(Dense(units = 3, activation = 'softmax'))
#하나로 모든 연산결과를 종합시켜줘 뻗쳐나간 방법을 종합하는 뉴런모델 Summary() 실행결과

- 모델 학습 및 compile
- model.compile 의 역할
- 지정한 모델이 효과적으로 구현될 수 있게 여러가지 환경을 설정하며 오차함수(loss)와 최적화 방법을 어떤 것을 사용할지를 정하는 부분. 모델이 해결해야할 문제(회귀/이진분류/다중분류)에 따라 달라진다.
- loss값의 변화
- 경사하강법 초반에는 w,b 값이 임의로 설정되어 있어서 loss값이 높았지만
조금만 학습해도 빠르게 loss값이 줄어드는 것을 확인할 수 있음.
- 모델 학습 시 제어하는 parameter 상세 설명
- epochs = 학습횟수
- batch_size = 샘플을 한 번에 처리하는 단위 수를 결정.
너무 크면 학습속도가 느려지고, 너무 작으면 각 실행값의 편차가 생겨서 전체 결과값이 불안정해짐.
- 경사하강법 초반에는 w,b 값이 임의로 설정되어 있어서 loss값이 높았지만
- model.compile 의 역할

#모델 컴파일 및 학습준비
model. compile(
loss = 'sparse_categorical_crossentropy', #오차를 어떤식으로 계산처리할 것인가
optimizer = 'adam', #각각의 뉴런 선형함수들을 경사하강법을 진행함.
#이때 경사하강법의 방법을 정해주는 것 현재는 adam 경사하강법으로 진행
metrics = ['accuracy'] #학습 후 평가방법. 현재는 정확도로 평가하라 명령
)
#문제, 정답, 반복할 횟수
model.fit(X,y,epochs=100, batch_size=10)
#모델 예측 평균값
model.predict(X).mean()- 모델 평가
#최종 모델 평가
model.evaluate(X,y)
#처음은 오차/ 뒤에가 정확도
# 실행결과
6/6 [==============================] - 0s 499us/step - loss: 0.2281 - accuracy: 0.9326
[0.2281111776828766, 0.932584285736084]

'기초 Coding > ML & DL' 카테고리의 다른 글
| [스마트인재개발원] 활성화 함수와 교차 엔트로피 (0) | 2021.12.20 |
|---|---|
| [스마트 인재개발원] Linear Model(선형 회귀모델)과 선형모델 평가요소 (0) | 2021.12.13 |
| [스마트인재개발원] 머신러닝 - 앙상블 모델_Voting, Stacking, Bagging, Boosting (0) | 2021.12.11 |
| [스마트인재개발원] 머신러닝 - 정규화 (0) | 2021.12.09 |
| [스마트인재개발원]머신러닝 - 교차검증 (0) | 2021.12.08 |



