
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 머신러닝
- randomForest
- 선형모델 분류
- ERD
- gitclone
- 1차프로젝트
- 내일배움카드
- 안드로이드
- 크롤링
- 2차프로젝트
- 오픈소스깃허브사용
- MVCmodel
- 비스포크시네마
- intent
- 하이퍼파라미터튜닝
- 교차검증
- 2차 실전프로젝트
- KNN모델
- 국비지원
- 프로젝트
- 백엔드
- 스마트인재개발원
- 손실함수
- 취업성공패키지
- springSTS
- MSE
- 취업연계
- JSP/Servlet
- semantic_segmentation
- 활성화함수
- Today
- Total
또자의 코딩교실
[스마트인재개발원] Ensemble Models - Random Forest, AdaBoost, Linear Regressor...etc 본문
[스마트인재개발원] Ensemble Models - Random Forest, AdaBoost, Linear Regressor...etc
또자자 2021. 12. 13. 14:18
- 이번 포스팅에서 다루는 모델들
- Random forest
- Ada Boosting
- Gradient Boosting Machine
- XGBoost(lightGBM)
Random Forest
과대적합을 이용해서 Bagging을 활용해 진행되는 머신러닝모델
작동방식
Random Sampling을 진행하여 서로 다른 방향으로 과대적합된 트리를 많이 만들고 평균을 내어 일반화 시킴.
각각의 변조된 데이터들을 다 만들고 모델에 돌려버린뒤 다수결로 밀어버리는 방식으로
최종 라벨값을 뽑아내는 모델
수정 가능한 Parameter들은 기존 Decision Tree 모델들과 동일하다
과대적합(Overfitting)문제를 회피하며 모델 정확도를 향상시키려고 개발되었음
| 장점 | 단점 |
| - 실제값에 대한 추정값 오차 평균화 - 과대적합 감소 - 큰 데이터 세트에도 잘 동작함 - 특성 중요도를 계산할 수 있어 다른 모델의 특성선택방법으로 활용가능 |
- 훈련과 예측이 상대적으로 느림 - 텍스트 데이터같은 비정형 데이터는 잘 동작하지 않음 - 트리 갯수가 많을수록 시간이 오래 걸림 |
분류면 해당하는 라벨값으로 Soft/Hard Votting이든 결정해서 밀어버릴거고
회귀면 라벨값들의 평균으로 밀어버릴거임
Python Code
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
#문제 정의 : 이진분류
#유방암 데이터를 이용하여 이 환자의 유방암 여부를 예측
data=load_breast_cancer()
data.keys()
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
#특성 데이터 (X)와 라벨데이터(y)를 훈련용과 테스트용으로 분리
X_train, X_test, y_train, y_test = train_test_split(data['data'],
data['target'],
test_size=0.3,
random_state=55)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
# n_estimators : 만들어줄 트리의 갯수
# random_state : 데이터 샘플링, 특성 선택시 랜덤하게 생성하는 난수의 무작위 시드값
# max_features : 사용가능하게 할 특성의 최대 갯수
forest = RandomForestClassifier(n_estimators=100,
random_state=0,
max_depth=5,
max_leaf_nodes=12)
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
#모델 학습 및 평가, 예측
forest.fit(X_train, y_train)
print("훈련세트 정확도 : {}".format(forest.score(X_train, y_train)))
print("테스트세트 정확도 : {}".format(forest.score(X_test, y_test)))
forest.predict(X_test[0:1])
X_test[0:1].shapeAdaBoost = max_depth =1
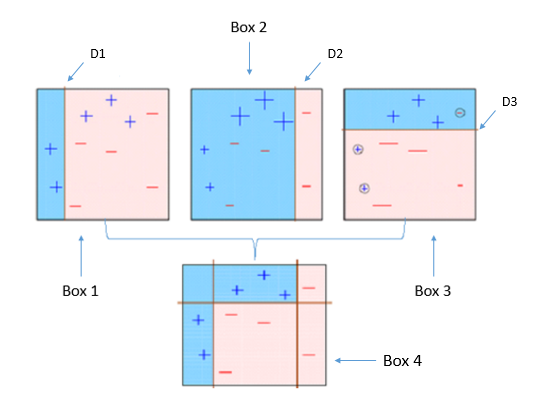
- Adaptive Boosting의 줄임말. 의사결정 트리 기반의 모델로 각각의 트리들이 독립적으로 존재하지 않음
작동방식
- ada boost 모델은 트리의 깊이를 1로 제한된 stump를 여러개 만듬
- 어떤 Stump는 다른 Stump보다 가중치가 높음
- (분류 질문에 따라 지니 불순도가 다름, 즉 Amount of Say 큰 stump가 존재함)
- 각 Stump의 error는 다음 Stump의 결과에 영향을 줌 (Boosting)
- 오차를 보완하는 방식으로 Boosting진행
- 좀 더 여러개의 특성을 사용하려면 n_estimator의 값(트리의 갯수)을 올려야함
- 최종 가중치 값을 합계로 구하게 되고, 가중 평균값이 최종산출 label이 된다.
- 가중평균값을 토대로 최종예측을 진행함
Python Code
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
#import
from sklearn.ensemble import AdaBoostClassifier
ada = AdaBoostClassifier(n_estimators=5, random_state=11)
# n_estimators : 만들어줄 트리의 갯수
# random_states : 데이터 샘플링을 결정할 난수 시드값
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
#모델 학습 및 평가
ada.fit(X_train, y_train)
print("훈련데이터 정확도 : {}".format(ada.score(X_train, y_train)))
print("테스트데이터 정확도 : {}".format(ada.score(X_test, y_test)))GBM(Gradient Boosting Machine) = 경사하강법
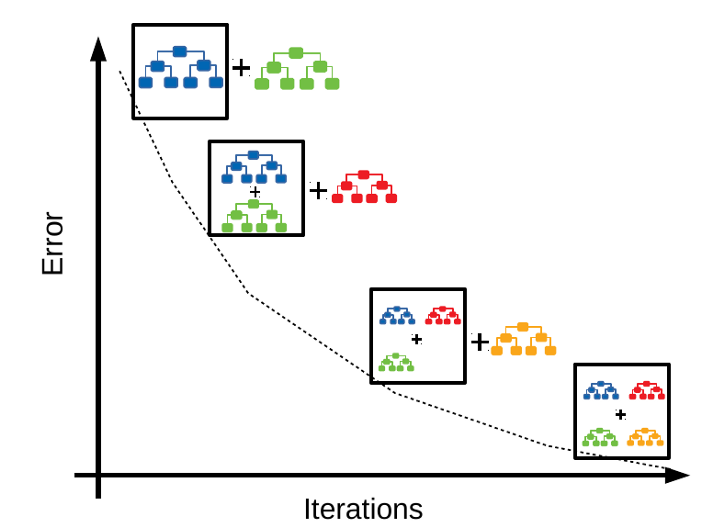
- 의사결정 트리 기반의 모델 : 분류와 회귀 모두 해결가능함.
- 오차를 보완하는 방식으로 Adaboost처럼 Boosting의 기본 Method로 동작함
- Random Sampling 없음 대신 강력한 사전 가지치기가 사용됨
작동방식
- max_depth 가 5이하인 tree model을 n_estimators의 수 만큼 만듦
- n_estimators가 커질수록 앙상블에 트리가 많이 추가되어 모델의 복잡도가 커지고 훈련 세트에서의 실수가 줄어듬
- 지정된 learning_rate에 따라 가중치를 변경하며 Boosting진행
- learning rate가 클수록 오차보정이 강해져 복잡한 모델이 되고 과대적합이 될 가능성이 높아짐
- 최종 가중치 값을 합계로 구하게 되고, 가중 평균값이 최종산출 label이 된다.
- 가중평균값을 토대로 최종예측을 진행함
- 보통 'max_depth < 5' 인경우가 많아 예측 속도는 빠른 편
- 변경가능한 parameter : learning_rate(오차 보정률), n_estimators(tree의 갯수)
- parameter만 조정 잘 해주면 더 높은 정확도를 제공함 Kaggle의 효자 모델
경사하강법
함수의 기울기를 점차 0으로 조정해 가면서 극값에 이를때 까지 반복함
기울기가 변화하는 정도를 중간으로 알맞게 맞춰줘야함
너무 작으면 극값을 일찍 찾을 수도 있어 정확한 극값을 찾지 못함
너무 크면 +무한대 로 발산 가능성이 높아짐

| 장점 | 단점 |
| - max_depth가 낮은 경향 >> 예측 속도 빠름 - scale 조정 need X - 특성 중요도를 계산할 수 있어 다른 모델의 특성선택방법으로 활용가능 |
- 매개변수 조정이 중요 - 이전 트리의 가중치를 변경해 새로운 트리를 만듦 >> 학습 속도 느림 - 과대적합 문제 - 텍스트 데이터같은 비정형 데이터와 희소한 고차원 데이터는 잘 동작하지 않음 >> XGBoost로 해결 - 트리 갯수가 많을수록 시간이 오래 걸림 |
Python Code
from sklearn.ensemble import GradientBoostingClassifier
#모델 선택
gb_model1 = GradientBoostingClassifier(random_state=0, max_depth=1, learning_rate=0.01)
#모델 학습
gb_model1.fit(X_train, y_train)
#모델 평가
print("훈련데이터 정확도 : {}".format(gb_model1.score(X_train, y_train)))
print("테스트데이터 정확도 : {}".format(gb_model1.score(X_test, y_test)))XGBoost
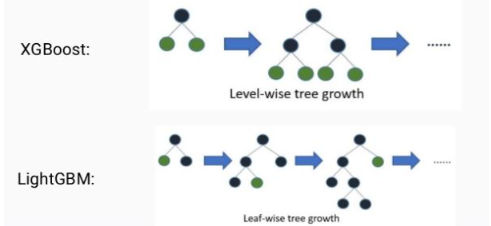
- 의사결정 트리 기반의 모델 : 분류와 회귀 모두 해결가능함.
- 대용량 분산처리를 위한 Gradient Boosting 오픈소스 라이브러리
- lightGBM : 히스토그램 기반 Boosting 알고리즘을 사용
- Early Stopping 기능을 제공
- 과대적합 방지를 위한 규제를 포함함
- objective -> binary:logistic (=이진분류), multi:softmax(=다중분류), reg:squarederror(=회귀)
- 손실함수 지정
- 회귀/분류 중 목적에 맞게 설정
튜닝해 볼 수 있는 파라미터
- learning_rate(학습률) : 높을수록 보정이 세짐. 과대적합 확률 증가
- n_estimators : 부스팅하는 나무의 갯수
- max_depth : 나무의 깊이
- reg_alpha (Lasso) : 다 동일한 힘으로 눌러서 특성선택이 자동으로 이루어짐
- reg_lambda (Ridge) : 다르게 분류된 힘들로 눌러줘서 좀 자동으로 하향평준화하는 규제가 이루어짐
- gamma (γ) : 값을 키우면 모델이 단순해진다. 값을 작아지게하면 모델이 복잡해진다.
(규제강도가 세질수록 lasso면 0이 되어버리는 모델이 많으니 단순해질것)
Python Code
!pip install xgboost
import xgboost
from xgboost.sklearn import XGBClassifier
xgb = XGBClassifier(random_state=0, learning_rate=0.1)
xgb.fit(X_train, y_train)
print("훈련 세트 점수 : {}".format(xgb.score(X_train, y_train)))
print("테스트 세트 점수 : {}".format(xgb.score(X_test, y_test)))
#경고창은 나중에 문제가 생길 수 있는것을 미리 알려주는 용도로 크게 상관안해도 됨
'코딩공부 > 기타 - 공부' 카테고리의 다른 글
| [배치파일 입문] 내 컴퓨터를 케이크처럼 쉽게 다루는 방법 (0) | 2022.05.12 |
|---|---|
| Parameter VS Hyper Parameter + how to find best hyper parameter (0) | 2021.12.08 |
| 피어슨 상관계수(Pearson Correlation Coefficient) (0) | 2021.11.30 |


