기업 및 단체에서 데이터와 해결과제를 등록하면, 데이터 과학자들이 이를 해결하는 모델을 개발하고 경쟁한다.
썸네일으로는 2022년에 새로운 타이타닉의 항해소식과... 침몰시켜 새로운 Dataset을 얻기 위해 눈독들이는 Kaggle Meme으로 골라봤다.
이번 포스팅은 상당히 길며, 머신러닝의 method에 따라 진행된다.
machine learning method
문제 정의
이번 포스팅에서는 실제 Kaggle 데이터인 타이타닉 데이터를 이요하여 머신러닝을 진행할 것이다.
사망여부를 예측하는 것이 최종 Label값이 되므로 결과값은 Yes, No 두가지 중 하나의 값이 된다.
이진분류문제(범주형 데이터)가 최종 예측값이 되게 된다.
사용하는 라이브러리는 다음과 같다.
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np # 시각화 라이브러리
먼저 Keggle에서 해당하는 데이터를 다운로드 받아보자.
케글 사이트에 접속하여 1번째 대회를 클릭!
Data Tab에 들어간 후 해당하는 데이터들을 다운로드 받아주자. gender_submission은 남자면 죽이고 여자면 살린 아주 단순한 정답 데이터이다. 이후 각각 train과 test로 나눠서 데이터를 설정해놓았다. train과 test데이터의 차이점은
Survived Column의 유무이다. 다운로드 받은 후 해당 파이썬 파일에 같은 폴더 내에 csv파일을 옮겨주자. 필자는 data폴더를 새로 만들어 그 안에 집어넣어 사용하였다.
다음은 python에 data를 불러온 방식이다.
test = pd.read_csv("data/titanic_test.csv", index_col='PassengerId')
train = pd.read_csv("data/titanic_train.csv", index_col='PassengerId')
#결측치 확인
train.isnull().sum(axis=0) # null값 여부가 T/F로 표시됨
test.isnull().sum(axis=0)
train.describe()
read_csv함수를 통해 두 함수를 불러오고 이제 isnull함수를 통해 결측치를 확인해보자. 원래 isnull함수는 null값의 여부가 T/F로 표시되지만 null값의 개수를 알기 위해 sum함수를 사용하여 axis=0(=열, 세로로 더하기) 으로 null값의 갯수를 모두 더했다.
두개의 데이터들을 모두 확인해보니 null값이 꽤 들어있다. cabin과 age쪽에 집중되어있는것을 확인할 수 있다. 머신러닝에 있어서 결측치(NaN값, Null값)는 데이터의 정확도를 떨어트리는 암적인 존재! 추후 데이터를 다듬는 과정에서 얘네들을 정돈시켜보자. 일단 가장 기본이 되는 데이터의 대략적인 정도를 확인하여 이상치를 다듬자.
Data 전처리 & 탐색적 데이터 분석
train data의 기본적인 표준편차부터 4분위수를 확인하는 코드이다. 보통 표준편차(std)에 평균가(mean)를더한 값보다 해당하는 데이터가 더 크다면 이상치라 보는 경향이 존재한다. 따라서 현재 Fare의 최대값은 이상치라 평가할 수 있다.
지금부터는..
- column과 다른 column간의 상관관계를 확인해보자. - Age 결측치 채우기 : 결측치가 많으면 데이터를 계산할 수 없음. - 단순 기술 통계치 (ex: 평균, 최빈값)으로 채우지 않고 다른 컬럼들과 상관관계를 이용해 결측치를 채워보자.
를! 할거에요
1. column과 다른 column간의 상관관계를 확인
column간 피어슨 상관계수를 확인할 수 있는 함수인 corr() 함수를 사용하여 column들간의 상관관계를 확인해봅시다.
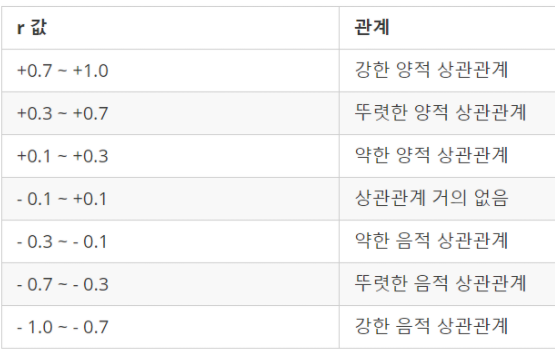
피어슨 상관계수란 피어슨 상관 계수(PearsonCorrelation Coefficient ,PCC)란 두 변수 X 와 Y 간의 선형상관관계를 계량화한 수치입니다.
피어슨 상관계수를 해석하는 법 = 1에 가까울수록 상관도는 비례하고 -1에 가까울수록 반비례한다. = 각 데이터가 완전히 동일하면 +1, 전혀 다르면 0, 반대방향으로 완전히 동일하면 -1의 값을 갖는다.
계수의 부호는 관계의 방향을 나타낸다. 두 변수가 함께 증가하거나 감소하는 경향(비례) 이 있으면 계수가 양수이며, 대체적으로 y=x의 그래프를 띄게 될 것이고, 한 변수가 증가할 때 다른 변수는 감소하는 경향(반비례)이 있으면 계수는 음수이며, 대체적으로 y=1/x의 그래프를 띄게 될 것이다. 극과 극이어도 연관도는 높으나 두 사이의 관계가 다를 뿐이다.
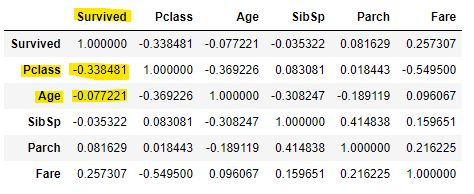
train.corr()
결과값은 다음과 같다. 결과여부를 보면 Pclass와 성별또한 생존여부와 높은 상관관계를 가지므로 함께 Grouping에 활용한다. 이후 그 정보들로 피벗테이블을 만들어 평균치로 나머지 빈 결측치들을 채워보자!
나이를 표시할때는 aggfunc='mean'을 활용하여 각각 Pclass, Sex에 따라 평균적인 나이를 출력하게 하였다.
train과 test의 결측치를 채우거나 데이터 전처리를 할 때에는 항상 train을 기준으로 데이터처리를 해야한다.
test를 기준으로 하면 답지를 보고 기워맞춰 데이터를 처리한것과 같다. 모든 학습은 train으로만 진행해야한다.
이제부터 Age column의 결측치를 채워보자.
How?
if(Age == null) >> 피벗테이블에서 평균 나이 가져오기.
else >> 원래 컬럼에 있던 row의 나이값을 가져오게 하자. 이 데이터는 train과 test에 모두 적용시켜야 하므로 파이썬 사용자 지정함수를 만들어 적용시킬것이다.
#사용자 지정함수 만들기deffill_age(row):#만약 row의 나이가 결측치라면 피벗 테이블에서 값을 가져온다. #나이가 결측치가 아니라면 원래 column에 있던 row['Age'] 값을 출력하면 된다. if(np.isnan(row['Age'])):
pclass = row['Pclass']
sex = row['Sex']
return pt1.loc[pclass, sex]
else:
return row['Age']
#사용자 지정함수 적용시키기
train['Age']=train.apply(fill_age, axis=1).astype('int64')
#apply함수는 전체 데이터프레임에 걸쳐서 내가 특정함수를 적용시키는 함수다.#apply함수는 행을따라서 적용할 수도 있고, 열을 따라서 적용할 수도 있다. #NaN값이 사라졌는지 확인하기
train.isnull().sum(axis=0)
train
isnull.sum의 결과로 확인한 NaN값의 총합. train의 Age의 결측치는 해결했으니 같은 방법으로 test의 Age결측치도 해결하자.
파이썬의 unique함수를 이용하면 Column에는 S, C, Q, nan등의 구성요소가 있음을 확인할 수 있다.
이후 파이썬의 value_counts함수를 이용하여 Embarked column내의 S,C,Q 의 갯수를 확인할 수 있다.
nan 결측치는 비어있는 값이므로 셀 수 없고 모든 갯수를 비교해 보았을때, 그 중 가장 수가 많은 S로 결측치를 채울 것이다.
train['Embarked'].fillna('S', inplace=True)
#결측치 채우는 함수 fillna#inplace 는 객체에 영향을 주는것의 속성을 제어한다. #inplace는 기본값으로 False를 가지고 inplace True를 입력하면 코드가 실행되면 바로 객체에 적용된다.
fillna 함수를 이용하여 결측치를 채우자. inplace를 True로 설정하여 코드가 실행되면 바로 객체에 적용되게하자.
train.isnull().sum(axis=0) 를 사용하여 Embarked 결측치가 사라진 것을 확인할 수 있다.
Fare 결측치 채우기
다른 column과의 상관관계를 이용하여 결측치를 채워보자.
파이썬의 corr() 함수를 이용하여 Pclass가 Fare column과 가장 높은 상관관계를 가짐을 확인할 수 있다.
일단은 성별을 함께 그루핑에 활용하여 Pclass와 Sex, Fare의 컬럼만 뽑아 통계치를 확인하고자 피벗테이블을 생성해보자.
수치형 데이터는 막대형태로 연속적으로 붙어있는데, 구간을 나눠서 표시하므로 bins 속성을 이용해 모든 속성을 몇개의 막대로 쪼개서 보여줄지를 걸정해야한다. (ex: bins =4는 나이들을 나타낼때 모든 속성들을 총 4개의 막대로만 쪼개서 뭉탱이로 보여주세요) 이러한 히스토그램은 기반 지식이 없다면 적절한 구간으로 나누지 못해 전혀 다른 해석이 될 수 있으므로 구간을 잘 쪼개줘야한다. 다음은 히스토그램을 만드는 코드이다.
plt.hist(train['Age'], bins=81)
plt.show()
실행결과는 다음과 같다.
히스토그램도 확인했겠다, KDE(Kernel Density Estimation)을 활용해 데이터를 시각화 해보자.
KDE는 히스토그램등을 스무딩하는 것을 말하는데, 커널함수(kernel function)을 이용한 밀도추정 방법중의 하나이다. 데이터의 밀도에 따라서 데이터가 많이 있다면 높게 그려주는 것을 데이터 커널 그래프라고 한다.
다음은 KDE플롯과 박스플롯을 합쳐놓은 형태의 시각화 도구인 Violinplot을 활용하여 성별에 따른 생존여부를 seaborn 라이브러리를 활용해 시각화하는 코드이다.
plt.figure(figsize=(15,5)) #그래프의 크기 조정
sns.violinplot(data=train,
y='Age', #밀도
x='Sex', #성별
hue='Survived',
split=True) #대칭성을 이용해 각각 바이올린마다 한쪽만 남기고 반으로 갈라 합치는 속성이다.
코드 실행결과
다음으로 SibSp과 ParCh column은 각각 형제자매/배우자의 수, 부모님/자식의 수를 나타내는데 두 컬럼을 합쳐서 가족이라는 새로운 컬럼을 생성한다면 보다 효율적인 데이터 활용이 가능할 것 같아 데이터를 묶은 후 시각화 하는 과정의 코드이다.
# Sibsp + Parch# Series형태는 numpy기반이므로 바로 연산이 가능하다. # Family_size 라는 새 컬럼을 만들어 갱신해줌.
train['Family_Size']=train['SibSp']+train['Parch']+1# 1을 더하는 이유 : 자기자신의 수 더하기
sns.countplot(data=train,
x='Family_Size',
hue='Survived')
실행결과는 다음과 같다.
다음은 Test data또한 Train data와 동일한 전처리를 진행하고
Family_Size Column의 연속적 데이터를 범주화하여 특성공학 데이터전처리를 진행하는 과정이다.
Family_Size가 1이면 Alone, 2~4면 Small, 5명 이상이면 Large범주로 변경할 것이며, cut함수를 활용해 진행하도록 했다. 여기서 cut함수는 초과-이하로 슬라이싱 하는 기능을 가지고 있다.
아래 Name 컬럼의 정보를 보면 Mr, Miss같은 호칭에서 성별을 표시하고 있음을 알 수 있다.
다음은 호칭을 "." 기준으로 잘라 1번째것의 데이터를 가지고 오는 코드이다.
train['Name'][89].split(',')[1].split('.')[0].strip()
# strip : 공백제거함수#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ#name column이 들어오면 전부 다 동일한 함수로 적용시켜버리는 사용자 지정함수 만들기defsplit_title(row):return row.split(',')[1].split('.')[0].strip()
#Apply함수로 만든 사용자 지정함수 적용하기
train['Title']=train['Name'].apply(split_title)
train.head()
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ#test데이터셋도 동일한 방법으로 적용defsplit_title(row):return row.split(',')[1].split('.')[0].strip()
test['Title']=test['Name'].apply(split_title)
test.head()
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ#데이터 시각화하기
plt.figure(figsize=(20,5)) #그래프의 크기 조정
plt.ylim(0,20)
sns.countplot(data=train,
x='Title',
hue='Survived',)
압도적인 Mr, Mrs, Miss 이외의 다른 적은 호칭들도 보이는데 나머지 호칭들은 인원수가 적고 종류가 많아 범주를 map함수를 이용해 통합시킬것이다. map함수는 딕셔너리 형태로 데이터를 replace하는 함수이다.
다음은 호칭을 통합하고 범주형으로 바꾼 값을 새 컬럼으로 생성하는 코드이다.
title_dic = {
'Mr' : 'Mr',
'Mrs' : 'Mrs',
'Miss' : 'Miss',
'Master' : 'Master',
'Mme' : 'Miss',
'Lady' : 'Miss',
'Don' : 'Other',
'Rev' : 'Other',
'Dr' : 'Other',
'Ms' : 'Miss',
'Major' : 'Other',
'Sir' : 'Other',
'Mlle' : 'Other',
'Col' : 'Other',
'Capt' : 'Other',
'the Countess' : 'Other',
'Jonkheer' : 'Other',
'Dona' : 'Other'# test에만 있는 데이터 여서 추가
}
print(train['Title'].unique())
print(test['Title'].unique())
#Dona -> test에는 있는데 train에는 없어서 nan이 반환되기에 title2 컬럼에 Dona를 Other로 전환해주자.#범주형으로 바꾼 값을 새 컬럼으로 생성
train['Title2']=train['Title'].map(title_dic)
train['Title2'].unique()
test['Title2']=test['Title'].map(title_dic)
test['Title2'].unique()
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ#실행결과 : array(['Mr', 'Mrs', 'Miss', 'Master', 'Other'], dtype=object)#통합된 모습 확인가능#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ#사용하지 않는 column들을 drop
train.drop(['Name', 'Ticket', 'Title'], axis = 1, inplace = True)
# 주의! ) dataframe은 2차원이기 때문에 어떤방향으로 삭제할지 적어주자.
test.drop(['Name', 'Ticket', 'Title'], axis = 1, inplace = True)
Data 모델링
이후 데이터 모델링을 활용해 모델 선택 및 하이퍼 파라미터 조정과 모델 학습 및 평가를 진행해보자.
기계는 숫자만 이해할 수 있기 때문에, 문자로 되어있는 데이터들을 모두 숫자로 바꿔주는 인코딩(encoding)이 필요하다.
인코딩에는 두가지 방법이 존재한다.
Label encoding과 one-hot encoding으로 나뉘게 된다.
1. label encoding : map()함수를 사용하여 숫자를 하나씩 대입하는것 - 컴퓨터가 분류의 기준인 범주형 데이터를 순서와 대소관계가 있는 수치형 데이터로 이해할 문제점또한 존재함. 2. one-hot encoding : column을 범주의 갯수만큼 만든 다음, 컬럼마다 만약 기존 데이터에서 해당하는 범주형 데이터가 맞다면 1을 표시하고 아니라면 0을 대입한다. - 1이라면 데이터가 있다, 0이라면 데이터가 없다는 뜻의 인코딩.
이 과정에서는 one-hot encoding을 진행하였고 다음은 원핫인코딩을 진행하는 코드이다.
categorical_features=['Sex','Cabin','Embarked','Family_Group','Title2']
##one-hot encoding한 결과를 확인할 수 있음.
pd.get_dummies(train['Title2'])
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ#for문 돌려 column앞에 식별하기 편하도록 prefix붙여 one-hot encoding하기for feature_name in categorical_features:
one_hot = pd.get_dummies(train[feature_name],prefix=feature_name) #원핫 인코딩#prefix:접두사. 단어 앞에 붙는 말으로 원핫인코딩을 진행하여 붙이겠다.
train.drop(feature_name, axis=1, inplace=True) #기존 문자형태의 컬럼 삭제#숫자로 된 범주형데이터로 된 column을 삭제하자.
train = pd.concat([train, one_hot],axis=1) #기존 데이터에 원핫 데이터 붙이기#Test dataset도 동일하게 원핫인코딩 진행for feature_name in categorical_features:
one_hot = pd.get_dummies(test[feature_name],prefix=feature_name) #원핫 인코딩#prefix:접두사. 단어 앞에 붙는 말으로 원핫인코딩을 진행하여 붙이겠다.
test.drop(feature_name, axis=1, inplace=True) #기존 문자형태의 컬럼 삭제#숫자로 된 범주형데이터로 된 column을 삭제하자.
test = pd.concat([test, one_hot],axis=1) #기존 데이터에 원핫 데이터 붙이기
prefix가 적용된 test 데이터셋.
현재 1개의 정답 label(Survivede)가 차이나야 하지만 현재 두개가 차이나기 때문에 train과 test의 컬럼명을 차집합 연산해보자. Series형태로 출력되는 데이터들은 numpy를 활용해 연산이 가능하다.
실행결과로 Cabin_T라는 컬럼명이 없는 것을 확인할 수 있다. 이는 원핫인코딩을 하다가 나온 컬럼으로
머신러닝을 진행할 때, column의 갯수가 맞지 않으면 계산이 되지 않으므로 test에 Cabin_T column을 만들되 데이터가 존재하지 않는다는 의미로 모두 0을 집어넣을 것이다.
#테스트 데이터에 Cabin_T 만들도 모두 0값 주기
test['Cabin_T']=0
test.head(1)
이후 Survived Column을 드랍시켜 순서를 맞춘다.
모델 학습 및 Validation(교차검증)
거의 다 왔다.!
거의 다 왔다!
지금부터 교차검증(Validation)을 진행해보자.
Validation
보통 train 과 test는 7대 3으로 나눔.
성능이 좋아질때까지 반복하여 데이터는 오직 test 데이터에 얼마나 정확도가 높은지만 판단하게 된다.
모르는 데이터는 정확성이 그동한 개발했던 모델과 정확하게 fit하지 못할 수도 있어 과대적합이 될 가능성이 있다.
실전에서 모르는 데이터로 쓰면 성능이 엉망이 될 수도 있어 train데이터>>만<< test데이터는 정말 최후의 보루로 놔두는셈 치고 거기에서 또 7대 3으로 train데이터를 쪼개어서 또 학습을 진행하고 결과를 보는 것을 validation이라 한다.
데이터가 충분하지 않다면? >> 학습시킬 수 있는 데이터를 많이 수집할거란 보장이 없음.
데이터가 몇개 없다면 학습시킬 양도 부족한데 그 안에서 테스트를 하려면 리스크와 부담이 크게 된다. \
전체적으로 일반화된 준비가 안되어 있을 수도 있음.
따라서 과대적합의 가능성이 일어날 수도 있다.
교차검증의 장점
보통 3번이나 5번정도를 잘라서 test데이터할 바통터치하듯 돌려 훈련과 학습을 진행한다. 이후 각각의 예측률을 다 모아서 평균을 낸다.
데이터가 한정적이어도 다섯번의 평가를 통해 데이터를 효율적으로 이용하기 쉽고 신뢰성이 보장된다.
모든 데이터를 train set과 test set으로 쓸 수 있다.
교차 검증으로 검증을 하고 교차검증으로 값이 정확하게 나온다면 그 모델로 실제 모델을 학습시키는 것
아래는 모델 선택과 모델 학습 및 평가 코드이다.
#모델 선택from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
knn_model = KNeighborsClassifier()
tree_model = DecisionTreeClassifier()
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ#학습시킬 데이터와 교차검증할 train data와 validation으로 각각 데이터를 분리from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, random_state=32)
#나눈값을 지정하지 않으면 보통 7대 3의 비율로 나뉘게 된다.#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ#모델 학습 및 평가
knn_model.fit(X_train, y_train)
tree_model.fit(X_train, y_train)
print(knn_model.score(X_val, y_val))
print(tree_model.score(X_val, y_val))
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ#교차 검증하기from sklearn.model_selection import cross_val_score
from sklearn.model_selection import StratifiedKFold
kf = StratifiedKFold(n_splits=17, shuffle=True, random_state=5)
# 5개로 자를거고, 섞을거고, 0번째 난수설정타입으로요!#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ#교차 검증 - knn model#교차 검증들의 평균치가 최종 예측값이 된다.
result = cross_val_score(knn_model, X_train, y_train, cv=kf)
result
result.mean()
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ#교차 검증 - tree model
result = cross_val_score(tree_model, X_train, y_train, cv=kf)
result
result.mean()
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ#Hyper Parameter Tunning - knn model
knn_score_list=[]
for k inrange(1, 150, 2):
knn_model = KNeighborsClassifier(n_neighbors=k)
knn_result = cross_val_score(knn_model, X_train, y_train, cv=kf)
knn_score_list.append(knn_result.mean())
plt.figure(figsize=(35,5))
plt.plot(range(1, 150, 2), knn_score_list)
plt.xticks(range(1, 150, 2)) #x축 : n_neighbors수(하이퍼 파라미터 값)
plt.grid()
plt.show()
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ#Hyper Parameter Tunning - tree model
tree_score_list=[]
for depth inrange(1, 150, 2):
tree_model = DecisionTreeClassifier(max_depth=depth)
tree_result = cross_val_score(tree_model, X_train, y_train, cv=kf)
tree_score_list.append(tree_result.mean())
plt.figure(figsize=(35,5))
plt.plot(range(1, 150, 2), tree_score_list)
plt.xticks(range(1, 150, 2)) #x축 : n_neighbors수(하이퍼 파라미터 값)
plt.grid()
plt.show()
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ#최종 모델 학습 및 모델링
final_knn=KNeighborsClassifier(n_neighbors=5)
final_knn_result=cross_val_score(final_knn, X_train, y_train, cv=kf)
print(final_knn_result.mean())
final_tree=DecisionTreeClassifier(max_depth=5)
final_tree_result=cross_val_score(final_tree, X_train, y_train, cv=kf)
print(final_tree_result.mean())
final_knn.fit(X_train, y_train)
final_tree.fit(X_train, y_train)
print(final_knn.score(X_val, y_val))
print(final_tree.score(X_val, y_val))
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ#최종 예측결과
knn_pre = final_knn.predict(X_test)
display(knn_pre)
tree_pre = final_tree.predict(X_test)
display(tree_pre)
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ#예측결과를 저장하고 케글에 제출하기#제출양식: submission 예측값들과 각각의 모델 예측값들 column들을 붙여서 Kaggle에 제출한다.#read_csv
submission=pd.read_csv("data/gender_submission.csv")
#knn model
submission['Survived'] = knn_pre
submission.head()
#csv파일로 df저장하기
submission.to_csv("data/knn_pre.csv", index=False)
#tree model
submission['Survived'] = tree_pre
submission.head()
#csv파일로 df저장하기
submission.to_csv("data/tree_pre.csv", index=False)
최종 제출 결과는 knn model이 66퍼의 정확률, tree model은 76퍼의 정확률을 보였다. 다음에는 별도의 포스팅으로 파이썬의 corr() 함수를 이용하여 Pclass가 Fare column과 가장 높은 상관관계를 가짐을 확인할 수 있던 부분에서 SibSp항목도 상관계수가 높은데 왜 같이 고려하지 않았는지가 의문이 들었다. 그래서 수업때 활용했던 것은 성별과 함께 그루핑에 활용했었지만, 다음 포스팅에는 SibSp를 이용하여 피벗테이블로 데이터들을 다듬어볼 생각이다.