
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 스마트인재개발원
- 취업연계
- 비스포크시네마
- KNN모델
- 오픈소스깃허브사용
- gitclone
- MSE
- 손실함수
- springSTS
- 교차검증
- MVCmodel
- 2차프로젝트
- 내일배움카드
- 취업성공패키지
- 1차프로젝트
- randomForest
- semantic_segmentation
- 백엔드
- 2차 실전프로젝트
- 머신러닝
- 크롤링
- JSP/Servlet
- ERD
- 프로젝트
- 선형모델 분류
- 안드로이드
- 하이퍼파라미터튜닝
- 국비지원
- intent
- 활성화함수
- Today
- Total
또자의 코딩교실
[스마트인재개발원] Kaggle 경진대회 (스압주의) 본문

스마트 인재개발원의 후반과정을 듣다보면 머신러닝을 배우게 된다.
이때 많이 어려운 머신러닝 공부도 더 하고 2차프로젝트의 탄탄한 기술적 배경을 다지기위해 자체적으로 Kaggle 대회를 개최한다.
Kaggle은 이전에 내 블로그 내에서도 타이타닉 분석을 통해 다룬적이 있지만, 캐글은 2010년 설립된 예측모델 및 분석 대회 플랫폼이다. 기업 및 단체에서 데이터와 해결과제를 등록하면, 데이터 과학자들이 이를 해결하는 모델을 개발하고 경쟁한다.
이번 Kaggle 대회의 문제는 이진분류 문제로, 쿠팡의 전자 상거래 물품 배송 예측이다.
즉, 물건이 제 시간에 잘 도착했는지, 도착하지 못했는지를 최종 예측하는 문제이다.

현재 총 24명(선생님 한분-팀)의 같은 과정을 수료하는 분들이 참여하고 있다. 한팀 당 6명이 경진한다.

현재 리더보드이다. 팀 멤버들과 최고예측 점수를 알 수 있다. 은근히 승부욕이 불타오를 수 있는 환경이다.

My submission 탭에서는 그동안 제출한 기록들과 점수의 진척정도를 확인할 수 있다.







다음은 Kaggle 대회 경진기간동안 내가 갱신한 모델들이다.
약간씩 점수가 오르는 모습을 확인할 수 있다. 0.588 >> 0.0674 (약 0.09%상승)
제일 기본적인 오타를 고치고 이상치를 처리하는 데이터 전처리와 null값을 채우는 방법들을 바꾸면서,
상관계수를 확인하면서 컴퓨터가 학습하는 모델들을 바꾸는 과정을 통해 꽤나 좋은 결과값을 얻게 되었다.

다음은 제출 할 때 사용했던 ppt와 함께 코드를 짚어보며 kaggle대회를 준비한 과정을 서술할 것이다.

다음부터는 기본적인 데이터 전처리의 과정이다.

#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
#기본적 오차 수정및 오타 수정
train_dic = {
' Ship' : 'Ship',
' Road' : 'Road',
' Flight' : 'Flight',
'?' : 'Ship',
' Shipzk' : 'Ship',
' Roadzk' : 'Road',
' Flightzk' : 'Flight'
}
train['Mode_of_Shipment2']=train['Mode_of_Shipment'].map(train_dic)
train.drop('Mode_of_Shipment',axis=1, inplace=True)
test['Mode_of_Shipment2']=test['Mode_of_Shipment'].map(train_dic)
test.drop('Mode_of_Shipment',axis=1, inplace=True)
train_dic1 = {
3 : 3,
4 : 4,
5 : 5,
1 : 1,
2 : 2,
99 : 3
}
train['Customer_rating2']=train['Customer_rating'].map(train_dic1)
train.drop('Customer_rating',axis=1, inplace=True)
test['Customer_rating2']=test['Customer_rating'].map(train_dic1)
test.drop('Customer_rating',axis=1, inplace=True)
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
#이상치 제거
train = train.replace(9999,200)
test = test.replace(9999,200)
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
#범주화
plt.hist(train['Cost_of_the_Product'], bins = 105)
plt.show()
bins=[0,150,200,250,350] # cut함수 특성 : 초과 - 이하
labels=['A','B','C','D']
# 구간 값을 가지는 새 컬럼 생성
train['Cost_of_the_Product_group']=pd.cut(x=train['Cost_of_the_Product'],
bins=bins,
labels=labels)
bins=[0,150,200,250,350]
labels=['A','B','C','D']
test['Cost_of_the_Product_group']=pd.cut(x=test['Cost_of_the_Product'],
bins=bins,
labels=labels)
train_dic2 = {
'low' : 'low',
'medium' : 'medium',
'high' : 'high',
'?' : 'medium',
'loww' : 'low',
'mediumm' : 'medium',
'highh' : 'high'
}
train['Product_importance2']=train['Product_importance'].map(train_dic2)
train.drop('Product_importance',axis=1, inplace=True)
test['Product_importance2']=test['Product_importance'].map(train_dic2)
test.drop('Product_importance',axis=1, inplace=True)
train = train.replace('?',np.NaN)
test = test.replace('?',np.NaN)
train['Weight_in_gms'] = pd.to_numeric(train['Weight_in_gms'])
test['Weight_in_gms'] = pd.to_numeric(test['Weight_in_gms'])
pt1 = train.pivot_table(values='Customer_care_calls',
index=['Cost_of_the_Product_group','Mode_of_Shipment2'],
aggfunc='mean'
)
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
#사용자 지정함수 생성 및 적용 - customer care calls
#prior_purchases & Discount Offered도 같은 방법으로 채워준다.
def fill_Customer_care_calls(row):
# 만약 row의 나이가 결측치라면 피벗테이블에서 값을 가져온다.
if np.isnan(row['Customer_care_calls']):
Cost_of_the_Product_group=row['Cost_of_the_Product_group']
Mode_of_Shipment2=row['Mode_of_Shipment2']
return pt1.loc[Cost_of_the_Product_group , Mode_of_Shipment2]
else:
return row['Customer_care_calls']
train['Customer_care_calls']=train.apply(fill_Customer_care_calls, axis=1).astype('int64')
test['Customer_care_calls']=test.apply(fill_Customer_care_calls, axis=1).astype('int64')
#결측값을 제외한 데이터로부터 선형회귀모형 훈련하기
from sklearn import linear_model
lin_reg = linear_model.LinearRegression()
X = train.dropna(axis=0)[['Customer_rating', 'Cost_of_the_Product', 'Mode_of_Shipment2']]
y = train.dropna(axis=0)['Prior_purchases']
lin_reg_model = lin_reg.fit(X, y)
#선형회귀모형으로 부터 추정값 계산하기
# Prediction
y_pred = lin_reg_model.predict(train.loc[:, ['Customer_rating', 'Cost_of_the_Product', 'Mode_of_Shipment2']])
# 결측치인 경우 훈련값, 아닌경우 기존값
train['Prior_purchases'] = np.where(train['Prior_purchases'].isnull(), pd.Series(y_pred.flatten()), train['Prior_purchases'])
#원핫 인코딩할 컬럼들
categorical_features=['Warehouse_block ','Gender','Mode_of_Shipment2','Cost_of_the_Product_group','Product_importance2','Weight_in_gms_group']
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
#컬럼들에 맞게 반복문 돌려 원핫인코딩하기
#원핫 인코딩하고 기존 train 테이블 옆에 새로 만든 원핫인코딩 컬럼 붙이기
for feature_name in categorical_features:
one_hot = pd.get_dummies(train[feature_name], prefix=feature_name) # prefix = 접두사
train.drop(feature_name , axis=1, inplace=True)
train = pd.concat([train, one_hot] , axis=1)
for feature_name in categorical_features:
one_hot = pd.get_dummies(test[feature_name], prefix=feature_name)
test.drop(feature_name , axis=1, inplace=True)
test = pd.concat([test, one_hot] , axis=1)
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
#훈련데이터(X_train)와 정답데이터(y_train) 분리
X_train=train.drop('Reached.on.Time_Y.N',axis=1)
y_train=train['Reached.on.Time_Y.N']
X_test=X_test[X_train.columns]

#할인율과 배송문의전화 도착여부 violin plot
sns.violinplot(data=train,
x='Customer_care_calls',
y='Discount_offered',
hue='Reached.on.Time_Y.N',
split=True
)
#구매경력, 배송문의전화, 도착여부 violinplot
sns.violinplot(data=train,
x='Prior_purchases',
y='Customer_care_calls',
hue='Reached.on.Time_Y.N',
split=True
)
#할인율과 구매경력, 도착여부 violinplot
sns.violinplot(data=train,
x='Prior_purchases',
y='Discount_offered',
hue='Reached.on.Time_Y.N',
split=True
)

# knn_model 하이퍼파라미터 튜닝 -train
knn_score_list = []
for k in range(1, 150, 2):
knn_model=KNeighborsClassifier(n_neighbors=k)
knn_result=cross_val_score(knn_model, X_train, y_train, cv=5)
knn_score_list.append(knn_result.mean())
# knn_model 하이퍼파라미터 튜닝 -test
knn_score_list2 = []
for k in range(1, 150, 2):
knn_model2=KNeighborsClassifier(n_neighbors=k)
knn_result2=cross_val_score(knn_model2, X_val, y_val, cv=5)
knn_score_list2.append(knn_result2.mean())
plt.figure(figsize=(30,5)) # (가로 , 세로)
plt.plot(range(1, 150, 2), knn_score_list)
plt.plot(range(1, 150, 2), knn_score_list2)
plt.xticks(range(1, 150, 2)) # x축의 n_neighbors수 (하이퍼파라미터 값)
plt. grid()
plt.ylabel('score')
plt.xlabel('n_neighbors')
plt.show()
# decision_tree 하이퍼파라미터 튜닝(max_depth 사용) -train
tree_score_list=[]
for n in range(1, 150, 2):
tree_model=DecisionTreeClassifier(max_depth=n)
tree_result=cross_val_score(tree_model, X_train, y_train, cv=5)
tree_score_list.append(tree_result.mean())
# decision_tree 하이퍼파라미터 튜닝(max_depth 사용) -test
tree_score_list2=[]
for n in range(1, 150, 2):
tree_model2=DecisionTreeClassifier(max_depth=n)
tree_result2=cross_val_score(tree_model2, X_val, y_val, cv=5)
tree_score_list2.append(tree_result2.mean())
plt.figure(figsize=(30,5)) # (가로 , 세로)
plt.plot(range(1, 150, 2), tree_score_list)
plt.plot(range(1, 150, 2), tree_score_list2)
plt.xticks(range(1, 150, 2))
plt. grid()
plt.ylabel('score')
plt.xlabel('max_depth')
plt.show()
from sklearn.ensemble import RandomForestClassifier
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
# 기본 랜덤포레스트(n_estimators = 100)
forest=RandomForestClassifier(n_estimators=100, random_state=0)
forest.fit(X_train,y_train)
print("훈련세트 정확도 : {}".format(forest.score(X_train, y_train)))
print("테스트세트 정확도 : {}".format(forest.score(X_val, y_val)))
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
# 특성중요도 시각화하기
def plot_feature_importance(model):
# 특성 갯수 구하기
n_features = len(model.feature_importances_)
# 수평 bar 차트 그리기
plt.figure(figsize=(15,10))
plt.barh(range(n_features),model.feature_importances_)
plt.xlabel('feature importances')
plt.ylabel('feature')
plt.yticks(range(n_features), X_train)
plt.show()
plot_feature_importance(forest)
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
# 랜덤 포레스트 하이퍼 파라미터 튜닝
forest_score_list = []
for k in range(1, 200, 2):
forest_model=RandomForestClassifier(n_estimators=k, random_state=0)
forest_result=cross_val_score(forest_model, X_train, y_train, cv=5)
forest_score_list.append(forest_result.mean())
forest_score_list2 = []
for k in range(1, 200, 2):
forest_model2=RandomForestClassifier(n_estimators=k, random_state=0)
forest_result2=cross_val_score(forest_model2, X_val, y_val, cv=5)
forest_score_list2.append(forest_result2.mean())
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
#하이퍼 파라미터 시각화
plt.figure(figsize=(30,5)) # (가로 , 세로)
plt.plot(range(1, 200, 2), forest_score_list)
plt.plot(range(1, 200, 2), forest_score_list2)
plt.xticks(range(1, 200, 2))
plt. grid()
plt.legend(True)
plt.ylabel('score')
plt.xlabel('max_depth')
plt.show()
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
#모델 학습
forest=RandomForestClassifier(n_estimators=2000, max_depth=129, random_state=0)
forest.fit(X_train,y_train)
forest.score(X_train,y_train)
forest.score(X_val,y_val)
from sklearn.ensemble import AdaBoostClassifier
# n_estimators : 만들어줄 트리의 갯수
# random_states : 데이터 샘플링을 결정할 난수 시드값
ada_model = AdaBoostClassifier(n_estimators=1000, random_state=11)
ada_model.fit(X_train, y_train)
print("훈련데이터 정확도 : {}".format(ada_model.score(X_train, y_train)))
print("테스트데이터 정확도 : {}".format(ada_model.score(X_val, y_val)))
from sklearn.ensemble import GradientBoostingClassifier
#모델 선택
gb_model1 = GradientBoostingClassifier(random_state=0, max_depth=1, learning_rate=0.01)
#모델 학습
gb_model1.fit(X_train, y_train)
#모델 평가
print("훈련데이터 정확도 : {}".format(gb_model1.score(X_train, y_train)))
print("테스트데이터 정확도 : {}".format(gb_model1.score(X_val, y_val)))
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
#learning rate제어
from sklearn.ensemble import GradientBoostingClassifier
#모델 선택
gb_model2 = GradientBoostingClassifier(random_state=0, learning_rate=0.01)
#모델 학습
gb_model2.fit(X_train, y_train)
#모델 평가
print("훈련데이터 정확도 : {}".format(gb_model2.score(X_train, y_train)))
print("테스트데이터 정확도 : {}".format(gb_model2.score(X_val, y_val)))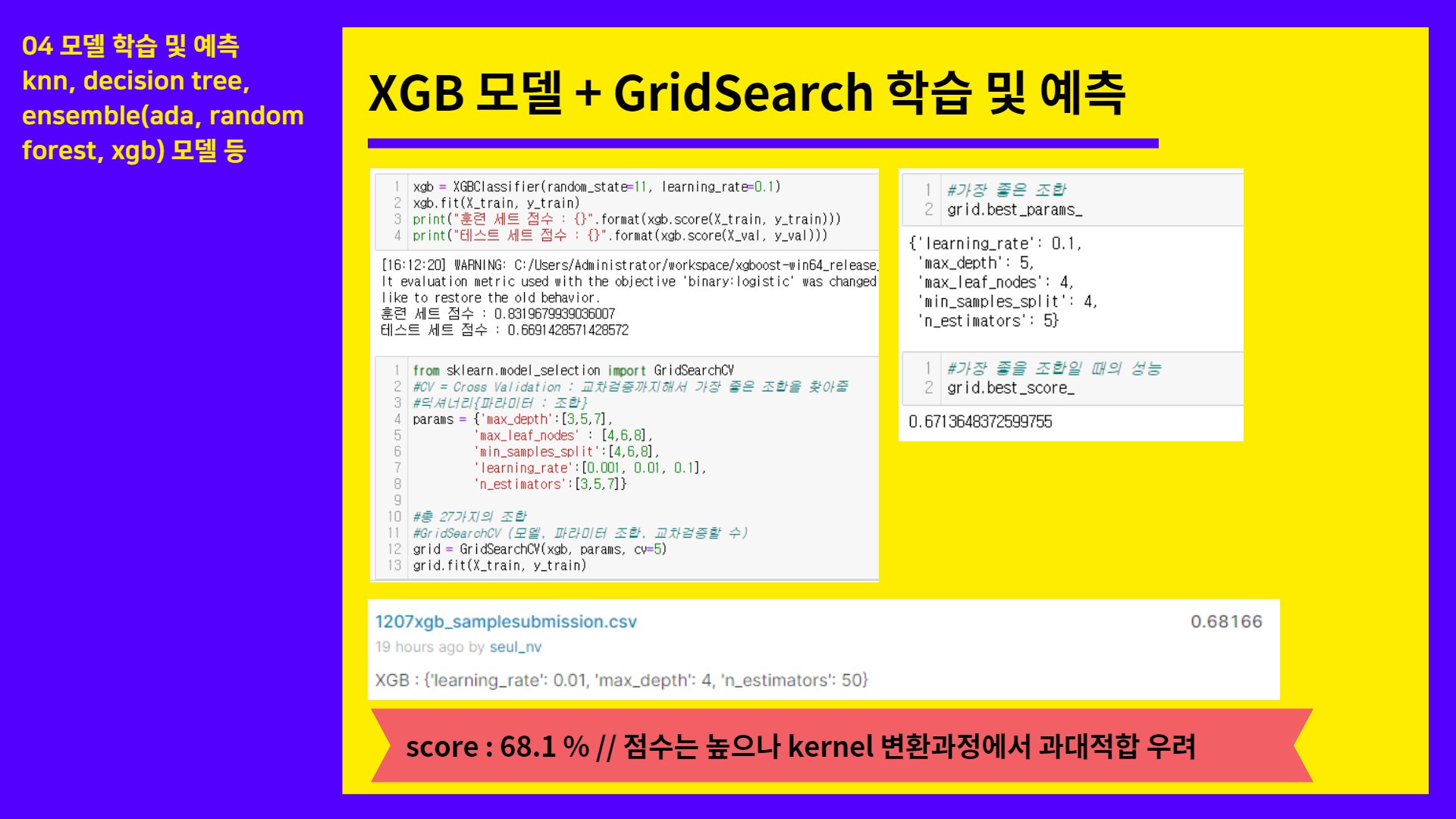
import xgboost
from xgboost.sklearn import XGBClassifier
xgb = XGBClassifier(random_state=11, learning_rate=0.1)
xgb.fit(X_train, y_train)
print("훈련 세트 점수 : {}".format(xgb.score(X_train, y_train)))
print("테스트 세트 점수 : {}".format(xgb.score(X_val, y_val)))
from sklearn.model_selection import GridSearchCV
#CV = Cross Validation : 교차검증까지해서 가장 좋은 조합을 찾아줌
#딕셔너리{파라미터 : 조합}
params = {'max_depth':[3,5,7],
'max_leaf_nodes' : [4,6,8],
'min_samples_split':[4,6,8],
'learning_rate':[0.001, 0.01, 0.1],
'n_estimators':[3,5,7]}
#총 27가지의 조합
#GridSearchCV (모델, 파라미터 조합, 교차검증할 수)
grid = GridSearchCV(xgb, params, cv=5)
grid.fit(X_train, y_train)
#가장 좋은 조합
grid.best_params_
#가장 좋을 조합일 때의 성능
grid.best_score_
# 가장 좋은 성능의 모델
best_model = grid.best_estimator_
'코딩공부 > 머신러닝 & 딥러닝' 카테고리의 다른 글
| [스마트인재개발원] 머신러닝 - Decision Tree 알고리즘(실습과 함께) (0) | 2021.12.08 |
|---|---|
| [스마트인재개발원] 근본중의 근본) iris 데이터를 활용한 KNN 분류실습 (0) | 2021.12.08 |
| [스마트인재개발원] 머신러닝을 통한 Kaggle 데이터 분석하기 (0) | 2021.11.29 |
| [스마트인재개발원] Machine Learning - KNN 알고리즘(실습과 함께) (0) | 2021.11.24 |
| [스마트인재개발원] Machine Learning - 일반화, 과대적합, 과소적합 (0) | 2021.11.24 |



