
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- 내일배움카드
- 안드로이드
- 크롤링
- 2차프로젝트
- MVCmodel
- gitclone
- 백엔드
- 하이퍼파라미터튜닝
- 취업연계
- randomForest
- 스마트인재개발원
- 오픈소스깃허브사용
- MSE
- ERD
- springSTS
- 선형모델 분류
- 국비지원
- 1차프로젝트
- semantic_segmentation
- intent
- 머신러닝
- 취업성공패키지
- JSP/Servlet
- 2차 실전프로젝트
- 활성화함수
- 손실함수
- 비스포크시네마
- 프로젝트
- 교차검증
- KNN모델
Archives
- Today
- Total
또자의 코딩교실
[스마트인재개발원]머신러닝 - 교차검증 본문

이번시간에는 과대적합을 막기위해 고안된 방법인 교차검증에 대해 알아보자.
Cross Validation(CV)이란?
학습-평가 데이터 나누기를 여러 번 반복하여 일반화 에러를 평가하는 방법이다.
K-fold cross-validation이란
Train data를 k번만큼 쪼개고 쪼개 얘네를 suffle 시켜서
여러개의 train data에서 임의로 짜집기한 가짜 test data로 정확도를 계산하는 과정을 k번 반복한 뒤,
최후의 test data로 최종 예측점수를 가져오는 방법으로 train data를 굉장히 낯설게 만드는 방법이다.
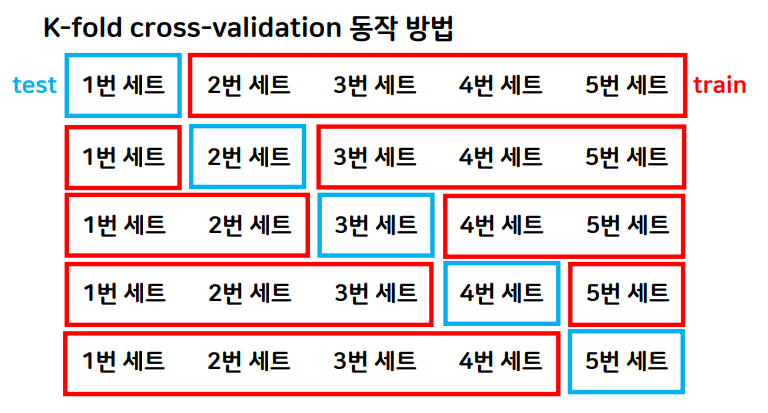
K-fold cross-validation의 동작방법에 대해 알아보자.
- 데이터 셋을 k개로 나눈다.
- 첫 번째 세트를 제외하고 나머지에 대해 모델을 학습한다. 그리고 첫 번째 세트를 이용해서 평가를 수행한다.
- 2번 과정을 마지막 세트까지 반복한다.
- 각 세트에 대해 구했던 평가 결과의 평균을 구한다.
교차검증의 장단점
- 장점
안정적이고 정확하다. (샘플링 차이를 최소화해 데이터의 여러 부분을 학습하고 평가해서 일반화 성능을 측정하기 때문이다.)
모델이 훈련 데이터에 대해 얼마나 민감한지 파악가능하다. (점수 대역 폭이 넓으면 민감)
데이터 세트 크기가 충분하지 않은 경우에도 유용하게 사용 가능하다.
- 단점
여러 번 학습하고 평가하는 과정을 거치기 때문에 계산량이 많아진다
교차검증은 cross_val_score함수로 진행된다. 실습코드는 다음과 같다.
from sklearn.model_selection import StratifiedKFold
kf = StratifiedKFold(n_splits=5, shuffle=True, random_state=0)
# 5개로 자를거고, 섞을거고, 0번째 난수설정타입으로요!
from sklearn.model_selection import cross_val_score
import numpy as np
#train / test 로 나누기전 데이터(전체데이터)를 이용한 교차검증
#score = cross_val_score(tree_model2, X_train, y_train, cv=5)
score = cross_val_score(tree_model2, X_one_hot, y, cv=kf)
score
#cv = n (n= n등분으로 쪼개서 교차검증할거에요)
#cv = kf (kf에 지정된 것 처럼 쪼개서 교차검증할거에요)
#교차실습 결과 평균 score
#score.mean()
np.mean(score)'코딩공부 > 머신러닝 & 딥러닝' 카테고리의 다른 글
| [스마트인재개발원] 머신러닝 - 앙상블 모델_Voting, Stacking, Bagging, Boosting (0) | 2021.12.11 |
|---|---|
| [스마트인재개발원] 머신러닝 - 정규화 (0) | 2021.12.09 |
| [스마트인재개발원] 머신러닝 - Decision Tree 알고리즘(실습과 함께) (0) | 2021.12.08 |
| [스마트인재개발원] 근본중의 근본) iris 데이터를 활용한 KNN 분류실습 (0) | 2021.12.08 |
| [스마트인재개발원] Kaggle 경진대회 (스압주의) (0) | 2021.12.06 |
'코딩공부/머신러닝 & 딥러닝' Related Articles
more




Comments